A council, not a single model.
Most AI tools trust whatever one model says first. This one runs a council of models — then rigorously checks their work, with the authorship hidden, before it commits to a single answer.
Ask
The same question goes to every model.
The council answers
Four models answer independently — four blind spots.
Anonymize
Authorship stripped — so no model can favor its own.
Peer review & rank
Every model grades every answer; the ranks are aggregated.
Chair synthesizes
A chair reconciles them into one reply.
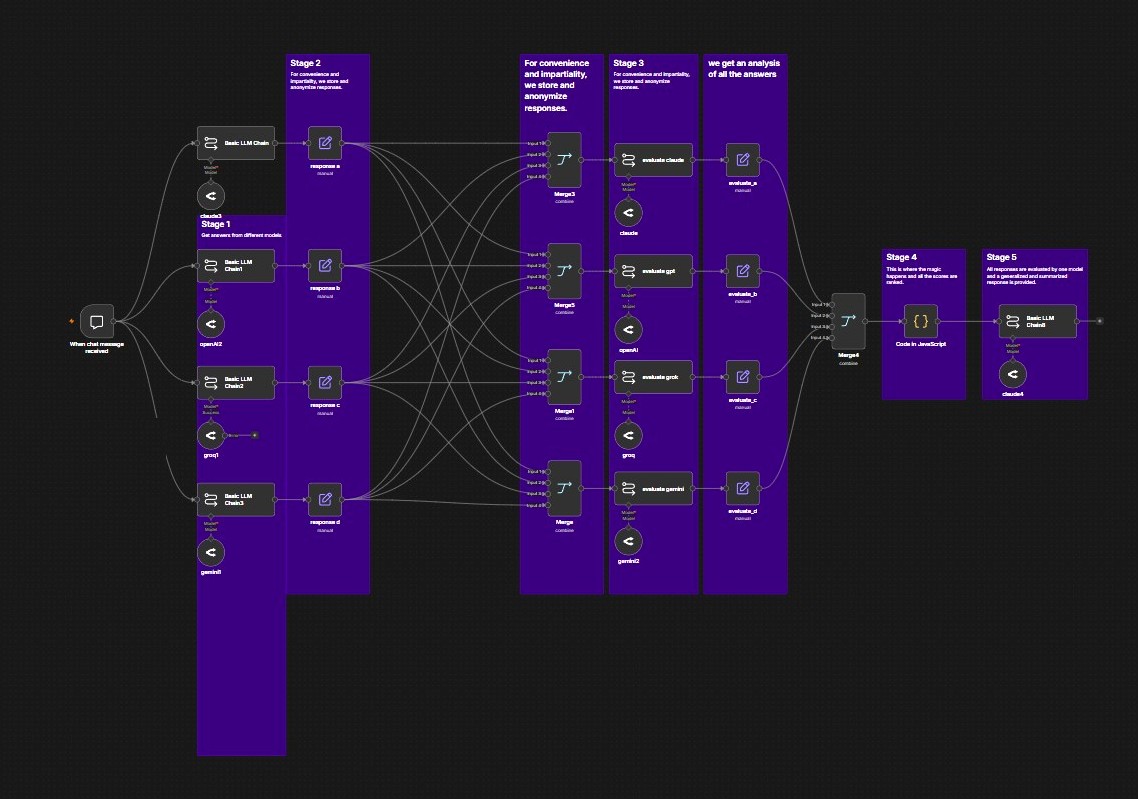
The secondary check is the whole point.
The easy version is one model that double-checks the answer. But a lone reviewer carries its own blind spots — and models reliably rate their own output highest.
So the answers are anonymized first, then the entire council ranks them and the scores are aggregated. No single judge dominates, and no model can play favorites — because it can’t tell which answer is its own.
| Reviewer | A | B | C | D |
|---|---|---|---|---|
| Claude | 2 | 1 | 3 | 4 |
| GPT | 3 | 1 | 2 | 4 |
| Gemini | 2 | 1 | 4 | 3 |
| Grok | 3 | 2 | 1 | 4 |
Act as the Strategy & Ops partner to the President of a specialty-ingredients distributor, post-acquisition: build this month’s account-priority system. Not SaaS — accounts are manufacturers and brands, every ingredient has its own margins, lead times, and launch horizons.
Anchor on risk-adjusted gross profit — est. revenue × margin × close probability — then decide where human attention changes the outcome.
“A pure revenue ranking fails. A pure pipeline ranking fails. A pure sample-count ranking fails.”
Attached: 12 anonymized accounts and 18 live opportunities — stages, margins, lead-time risk, communication signals.
override: broken-signal opportunities are barred from scarce technical pushes until sales repairs the signal
Top of the ranking: a new incubator account’s ferment-based active — $190k × 28% × 40% ≈ $21k expected GP, lifted by very-high headroom and a maximum leverage flag: strong R&D pull, no executive sponsor yet → presidential visit.
One model is one set of blind spots. Four independent answers surface more, and disagreement is signal — it flags where the question is genuinely hard.
Evaluators favor their own writing. Hiding authorship turns peer review into a fair test of the answer, not a popularity contest between brands.
Aggregated ranks pick the strongest answer; the chairman reconciles where the council agrees and disagrees into one clean, usable reply.
An AI-native operator: I stand up working AI systems and engineer them for reliability — not just call an API.